CS 3113 Spring 21
This is the web page for Operation Systems at the University of Oklahoma.
Introduction to Operating Systems
CS 3113, Spring 2021
Project 0 (Due 3/2 3/9 end of day)
When opening text files, most people only look at the extension of the file to determine the file type extension (e.g. txt, pdf, docx). File type extensions in Linux can be changed as easily as changing the file name. When opening a text file, there are scores of byte encodings that must be decoded and displayed to the user. In this project, you will write a program to read input bytes from the stdin and count and record the occurrence of each character in the file. At the end of the file or when the file is closed, you will write to stdout the list of characters sorted by the number of times the characters appear in the input in order of greatest to least. note: some characters may be invisible but they shuold still be printed.
After doing this project you will have a deep understanding of byte and bit manipulation in C, data structures in C, Unicode, and UTF-8. Each of these skills are important for practical computer science.
Proper Academic Conduct
The code solution to this project must be done individually. There are many Unicode parsers available, do not use the internet to copy solutions to this problem from the network and do not look at or copy solutions from others. However, you may use the Internet for inspiration and you may discuss your general approach with others. To avoid academic dishonesty violations, add all your sources of inspiration to your COLLABORATORS file.
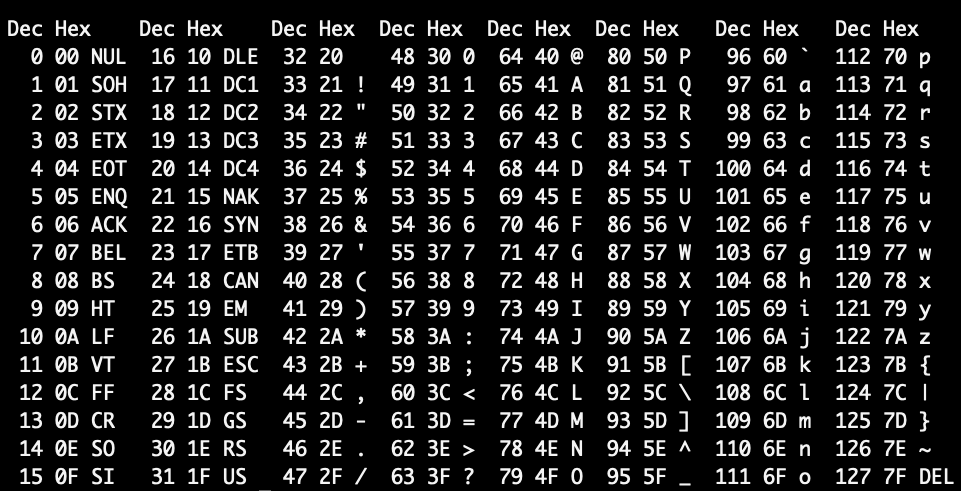
ASCII
The initial Unix/Linux implementations assume a small set of common characters. In 1963, ASCII was first as a seven-bit code that points to all usable characters. Because seven bits are used, ASCII can only include 2^7 or 128 different characters. This limits the number of characters to a subset of English Roman-based alphabets. Because many programming languages and applications have assumed everyone is using ASCII, serious file recognition issues have emerged.
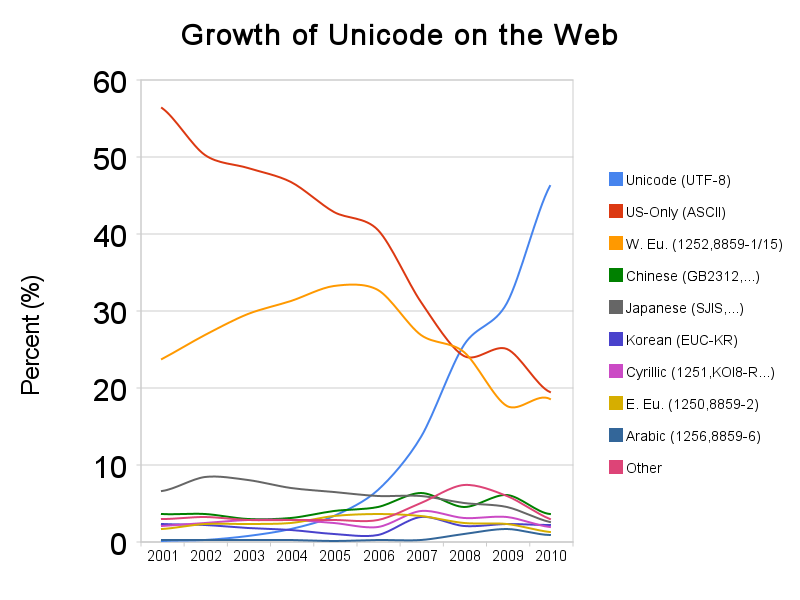
Around 2008, Unicode and UTF-8 over took Unicode as the most popular web file type encoding. The web is world wide and this trend has only increased. Below we introduce Unicode and UTF-8.
About Unicode and UTF-8
The Unicode standard was developed as a way to encode all of the characters in every language. Unicode is a collection of agreed upon mapping characters (⌛️,⏰️) to a numerical representation called and code points (U+231B, U+23F0). Currently, there is room for 1.1 million characters in the Unicode standard but only ~137K are currently being used. The standard is regularly assigning new characters to codepoints.
UTF-8 is the Unicode Transformation Format, it is a variable-sized encoding for Unicode. It is used to encode text of any language. UTF-8 maps the code point defined in Unicode to a binary representation. Browsers, terminal, and editors, if they know the encoding of the text file (e.g. UTF-8), they can translate the binary representation to the Unicode code point and then the glyph.
In this project, your code will need to read the binary encodings of a UTF-8 file and count/print all of the characters in the document.
UTF-8 Example encoding
In this first example, let’s assume that we are looking at the thorn character in a file (Þ).
We can look up this character on the helpful unicode-table.
We can see that the Unicode code point is U+00DE.
If we add this character to thorn.txt and call hexdump we can see the byte representation of the thorn character.
What we are looking at is the UTF-8 encoded representation.
Some things to remember when looking at hexdumps: (1) each number in the is a nibble and two nibbles make a byte. (2) the representation is little endian, so the first byte is the least significant byte.
cgrant@instance-1 % hexdump -x thorn.txt
0000000 9ec3
0000002
Translated to bytes, the UTF-8 encoded bytes is 11000011 10011110
We can see that it one character stored as two bytes.
Before explaining how the encoding works, lets take a look at one more example.
Lets assume we have a file with only one emoji character (⌛️).
We can look up this character on helpful unicode-table website.
The name of this character is Hourglass, the Unicode number is U+231B.
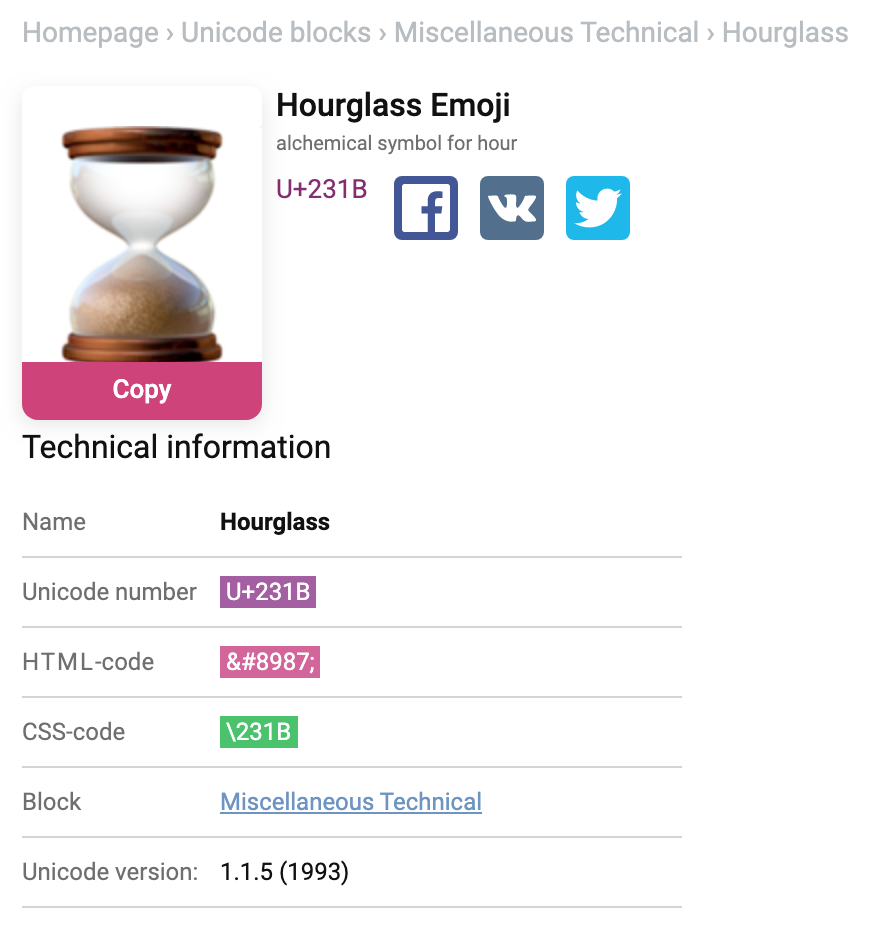
If we copy and paste this emoji into a file on our *nix based systems (and remove any extra characters like trailing new lines) we can observe the hexadecimal and binary representation of the file. This emoji is three bytes long.
cgrant@instance-1 % hexdump -x hourglass.txt
0000000 8ce2 009b
0000003
Knowing this, and that the hex representation is in little endian form, the UTF-8 binary representation is:
11100010 10001100 10011011
Translating between UTF-8 and Unicode
The detection scheme for UTF-8 characters follow just a few rules:
- The high-order but in binary is always important.
- If the high-order bit is zero, then only one byte is needed and the representation of the current character is ASCII.
- If the high order bits are [110], then the Unicode character will be two bytes long. Also this means that the next byte must have a 1 in the high order bit and the second bit 0.
- If the high order bits are [1110…], then Unicode will be three bytes long. Also, the next two bytes should have a one in the high order bit and the second bit 0.
- This pattern will follow with 4 byte encoding and larger.
In the first example above, the bit representation of the thorn character is 11000011 10011110.
The two ones in the high order bit tell us that this character is two bytes long.
According to the rule, the second byte also has a 1 in the high order bit.
Here we we put boxes around the UTF-8 control bits:
[110]00011 [10]011110.
If we just look at the bytes used to represent the code point we get
00011 011110 -> 000 1101 1110 -> 0 D E.
You will notice that this is the exact code point representation!
In the second example, we will progress through the bytes in the same way.
11100010 10001100 10011011 ->
[1110]0010 [10]001100 [10]011011 ->
0010 001100 011011 ->
0010 0011 0001 1011 ->
2 3 1 B
Voilà! Exactly the code point.
Assignment Instructions
Now that you understand byte representations of Unicode code points using UTF-8 you need to use loop through the file and count the occurrences each character. Then, you should sort the collection from largest to smallest and write the characters along with their occurrences to the stdout file. If there is a tie, the character that appears first if input file should appear first in the output.
Here is an example run of the program
First make clean is called to clear out an old binaries.
The make all is called to compile the executable.
We assume that a file is in local directory called test1.
We use cat to out put the contents of test1.
The | symbol reads stdout from test1 and writes it to stdin of the project0 program.
When project0 is run it reads from stdin and writes to stdout all of the characters in order of the number of times they appear.
The characters and the counts are separated by a dash and the greater than sign (->), and a new line is on each line.
% make clean
% make all
% cat test1 | ./project0
->1839
m->1799
h->1656
d->1550
g->1256
b->1196
y->1065
...
а->495
р->287
н->272
ɛ->260
и->240
ɔ->218
д->210
у->197
о->189
т->185
ا->184
...
Submission
We encourage you to create a private github repository with the name cs3113sp21-project0.
Add collaborators cegme and liuyunl777 by going to Settings > Manage Access. (Or Settings > Collaborators in older version of GitHub).
Your repository should have, at least, the following files:
/cs3113sp21-project0
├── .gitignore
├── Makefile
├── project0.c
├── README
└── COLLABORATORS
When you are ready to submit, open the assignment’s submission area on Gradescope. You may make a submission by either uploading directly from your computer or linking to a GitHub or BitBucket repository. Gradescope will allow you to make multiple submissions, and get rapid feedback on those submissions.
Please make sure that you upload all of the required files:
Makefile
Include a makefile with the standard targets all and clean.
The make all command should create an executable project0.
The make clean target should remove executables and temporary files.
README
The README file should be all uppercase with either no extension or a .md extension.
Don’t use .txt or anyother extenstion.
You should (1) write your name in it, (2) a usage example of how to compile and run it, (3) any bugs that should be expected, and (4) a list of any web or external libraries that are used.
The README file should make it clear contain a list of any bugs or assumptions made while writing the program.
Note that you should not be copying code from any website not provided by the instructor.
Using any code from previous semesters or students will results in an academic dishonesty violation.
You should include directions on how to compile and use your code.
You should describe all functions method in the README file.
When describing any known bugs and sources be sure to include any assumptions you make for your solution.
COLLABORATORS file
This file should contain a pipe separated list describing who you worked with and a small text description describing the nature of the collaboration. This information should be listed in three fields as in the example is below:
Katherine Johnson | kj@nasa.gov | Helped me understand calculations
Dorothy Vaughan | doro@dod.gov | Helped me with multiplexed time management
Stackoverflow | https://example | helped me with a compilation but
Deadline
Your submission/release is due on Thursday, March 2st at the end of day. The late policy of the course will be followed.
Grading
Grades will be assessed according to the following distribution:
- 80%: Correctness.
- This will be assessed by giving your code a range of inputs and checking the output.
- 20% Design and Readability. This category includes:
- The README file should be complete and descriptive.
- Correct and efficient code implementation
- Appropriate choice of function and variable names
- The COLLABORATORS file should be properly formatted and reflect all resources used.
Helpful resources and references
- Unicode nearing 50% of the web
- Stackoverflow: What is the difference between UTF-8 and Unicode
- Introduction to UTF-8 and Unicode
- unicode-table.com
- Removing the new line using vim
- The website explainshell.com is helpful in understanding some combinations of command line programs.
- Review the Linux Manual pages for refreshers on how to use
dprintf,fprintf,open,close,malloc, etc.
Using xxd or hexdump to view file contents
echo "a" | xxd
00000000: 610a
echo "a" | xxd -b
00000000: 01100001 00001010
echo "a" | hexdump -x
0000000 0a61
0000002
echo "😀" | hexdump -x
0000000 9ff0 8098 000a
0000005
Addendum
- 2020-02-24 - Updated the project due date to 3/9