Comparing Machine Learning Classification Approaches for Predicting Expository Text Difficulty
Comparing Machine Learning Classification Approaches for Predicting Expository Text Difficulty Renu Balyan, Kathryn S. McCarthy, Danielle S. McNamara, FLAIRS-31
Text analysis is a popular research field. Predicting text difficulty is one of the most challenging tasks in text analysis. The educators can benefit from the study of the difficulty of the text. Given the difficulty-classified reading materials, educators are more confident to select them to meet the need of individual student. In this paper, Renu, Kathryn and Danielle conduct a series of experiments to discover the promise and limitations for applying hierachical approches to text difficulty classification.
Feature selection
The authors’ experiment use more sophisticated linguistic features to evaluate text difficulty.
- Readability: Simple measures of readability (Flesch-Kincaid , L2 learners)
- Lexical Diversity: Variety of words used in the text (TTR, MTLD)
- Uncommon or Rare words: Words that are uncommon or occur rarely in English language
- Syntatic Complexity: Mean number of words before the main verb
- Concreteness: The degree to which a word is non-abstract
- Imagability: How easy it is to construct image of a word in one’s mind
- Familiarity: How familiar a word is to an adult
- Age of Acquisition: The age at which a wod first appears in a child’s vacabulary
Running the experiment
Two sets (Non-Hierarchical and hierarchical) of experients are applied to the three data set A, B and A+B. Set A is from the iSTART StairStepper module, including texts that varied widely in genre and difficulty (1–12), while Set B from iSTART’s main text library which is used in high school and college science courses and varied in difficulty (6–14). Set A+B is the combiniation of the Set A and Set B.
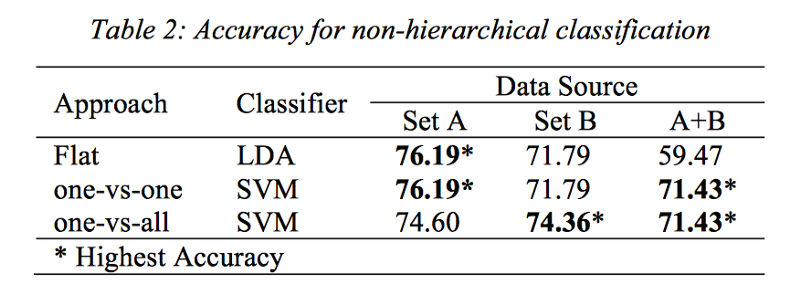
LDA, one-vs-one SVM and one-vs-all SVM are used to mine the text difficulty. The following show the accuracy for non-hierarchical classification.
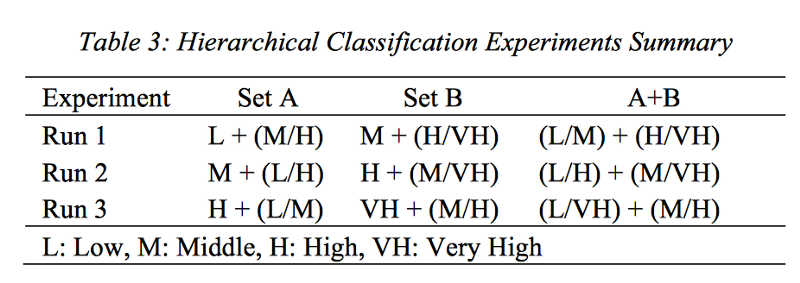
For hierarchical classification, authors conducted three runs’ experiments. The experiments’ summary is shown in Table 3. For example, in the first run of Set A, the texts are classied as ‘low’ and ‘other’. At second level, the ‘other’ class are partitioned into ‘middle’ and ‘high’.
The classification result is summarized in the Table 4.
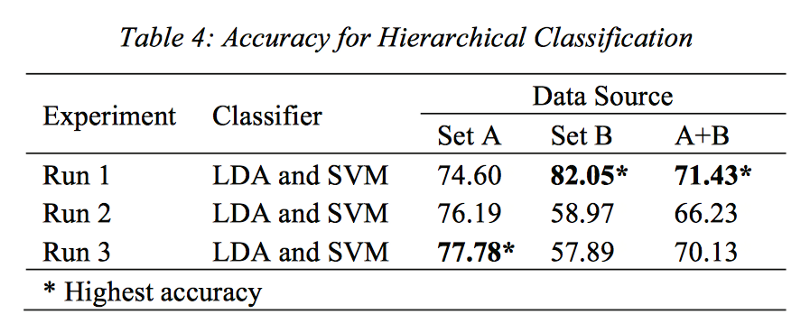
The hierarchical approach is promising for text difficulty classification. It achieves the higherst accuracy for Set A (77.78) and Set B (82.05). For A+B dataset, both hierarchical and SVM approaches achieve the highest accuracy (71.43%).
Discussion
Not all runs of hierarchcal classification experiments achieving higher accuracy than non-hierarchical classification indicates some unknown factors for such results. Moreover, when the two test sets were combined, hierarchical classification doesn’t show the promise for this task. The difference between the middle and high text sets are not significant, and it might affect the performance of the hierarchical classification.