Human-in-the-Loop Data Analysis: A Personal Perspective
Human-in-the-Loop Data Analysis: A Personal Perspective Doan, AnHai, Proceedings of the Workshop on Human-In-the-Loop Data Analytics. ACM, 2018.
Taxonomy of data problems
This paper talks some big picture questions for HILDA community. Starting with the taxonomy of data problems that needs human to get involved shown in the figure below.
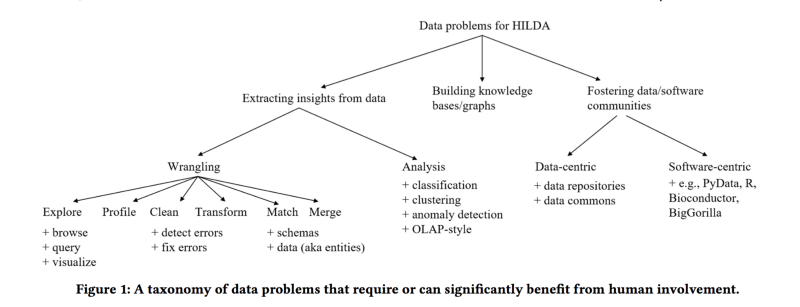
Author categorize the data problems for HILDA to three major aspects: extracting insights from data, building knowledge bases/graphs and fostering data/software communities.
From left subtree, data wrangling has more tasks than data analysis. Data wrangling plays an intial and important role in the process, it preprocesses the data by exploring, profiling, cleaning, transforming, matching and merging. For the left part of extracting insight from data subtree, data analysis is performed by running various algorithms for different data mining tasks such as classification, clustering, anomaly detection and OLAP-style.
In the middle, building knowledge bases/graphs can require or benefit from human interaction. Interestingly, fostering data and software communities draw the attention by the author, since the communities grows rapidly in recent years. Data-centric communities such as data repositories and data commons and software-cetntric e.g., PyData, R, are two major part under this category related to HILDA comunnity.
Except categorizing the problem, author also specifies three dimentions for human involved in HILDA: size, technical sophistication and role in the data mangement process. We can clarify a problem related to HILDA by considering those aspects described previous. It helps us to understand the problem in HILDA domain.
Developing the solution
In this paper, some aspects for developing HILDA solutions are discussed. Author emphasizes the practical issue for solve problems that real users care about.
Trying to work with and solve their problems is often an eye-opening experience, which can quickly drive home where the real “pain points” are, and thus which problems should be addressed.
Real-world problems can be promising to adjust the direction of the academic research. The author is optimistic about the need for a human loop. New problem solving requires consideration about the existing system. Author points out the weakness on On-premise system and Cloud-hosted system and inspires HILDA community to devote more attention in both kinds of sytems. Benchmark and challenges should be consider as the issue to make for achieving progress in HILDA community. Building a theory system of human data interaction can benifit the research group of HILDA. In this part, an interesting area is mentioned:
They exhibit certain biases and behaviors when making decisions under uncertainty.
Biases as the output of the process of HILDA is inevitable in current situation. Biases in the data affect human to make a fair decision and it could be ignored by human. Understanding these issues can help HILDA community to build appropriate solutions.