Exploring the Utility of Developer Exhaust
Exploring the Utility of Developer Exhaust
Zhang, Jian, Max Lam, Stephanie Wang, Paroma Varma, Luigi Nardi, Kunle Olukotun, and Christopher Ré, Proceedings of the Second Workshop on Data Management for End-To-End Machine Learning, p. 7. ACM, 2018.
In this paper, author uses machine learning to explore developer exhaust which is byproducts of the data processing pipeline, such as logs, code and metadata. They mentioned that users rarely use those developer exhaust systematically, usually manually check them. They explore how to use exhaust to simplify complex downstream tasks, e.g., model search.
Log data is the main focus in the paper. Training logs are generated by models designed and trained by developers. Logs contains information about the performance of the models, e.g. training time, memory usage etc. Using those information found in logs can aid complex task such as model architecture search which search for the best-performing model design for a specific task or methods training candidate architectures to convergence to find the best model architecture. The figure below shows their method predicting the performance of untrained architectures by using information present in logs of pre-trained architectures.
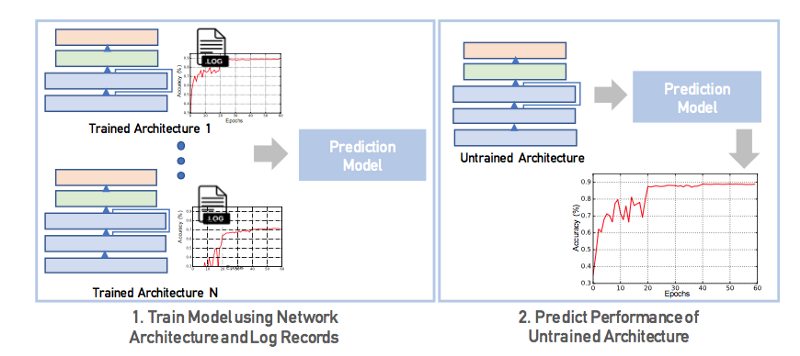
They define an edit distance between model architectures and predict model performances using nearest-neighbor approach. They design a LSTM-based regressor which serialize hyperparameters of a model as a sequence of tokens and train an LSTM without any manual featurization to predict performance characteristics of an untrained model.
In the evaluation, predicted performance of untrained model based on trainging logs of other models close to true performance.
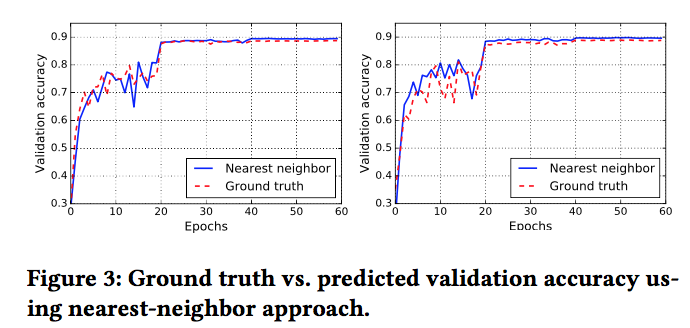
Their simple models can predict validation accuracy of a model within 2% of the true performance, and their method can predict performance given a constraint on training time.