OU DALab @ HILDA workshop (SIGMOD Series)
We began the our week-long SIGMOD experience by attending the HILDA workshop. This workshop was beneficial for all of our lab members especially those working on projects relevant to HILDA concepts.
“HILDA (Human-In-the-Loop Data Analytics) is a workshop that allows researchers and practitioners to exchange ideas and results relating to how data management can be done with awareness of the people who form part of the processes” (HILDA website).
This workshop was co-located with SIGMOD 2018 in Houston, Texas. The HILDA workshop was apart of the initial series of workshops that began the SIGMOD conference.
The program chairs for the HILDA 2018 workshop were:
- Carsten Binnig (TU Darmstadt, co-chair)
- Juliana Freire (New York University, co-chair)
- Eugene Wu (Columbia University, co-chair)
This workshop hosted many more interesting talks and presentations through out the day. Beyond networking and learning, we had the pleasure of supporting our lab member, Shine Xu, who presented his work on Simpson’s Paradox Detection at the HILDA workshop.
Here’s a overview of his work:
Interactive Visual Analytics for Simpson’s Paradox Detection.
Shine Xu (University of Oklahoma)
Simpson’s paradox is the statistical phenomena where two variables, when conditioned on a third, exhibit the opposite relationship in correlation to] of the entire data set. A synthetic example is given below:
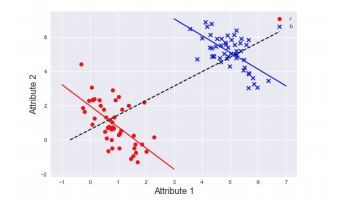
Synthetic Simpson’s ParadoxIn the image, above one can see that the data set as a whole has an upward trend, while the two halves (red and blue clusters) have the opposite trend. This paradox is found in many popular data sets and leaving it unaddressed may lead to wrongful predictions on a seemingly well performing model.
The algorithm employed to detect this paradox employs a simple search of pairs of candidate attributes over their categorical counterparts. The algorithm is formally described here:

Formal Detection AlgorithmFirstly, the correlation over the entire data set is computed for future comparison. Next, all the categorical attributes are collected and grouped across all existent classes (i.e., a variable ranging between the values ‘male’ and ‘female’ would be grouped into those two categories). For each of these classification groups, the correlation between two continuous variables (for all continuous variables) conditioned on the group value is measured against that of the whole data set. If these correlations are opposite of each other, this information is added to a positive result.
Experiments were carried out on two data sets: the Iris data set and Auto MPG data set. The Iris data set was found to contain nine instances of Simpson’s Paradox, and the Auto MPG data set was found to contain six instances of Simpson’s Paradox.
Takeaways: In the beginning phases of investigating Simpon’s Paradox (SP), opposite trends were clearly identified in the datasets but this methodology has the potential to be expanded to exploit biases in real life problems (e.g. prison incarceration rates, college acceptance rates, and death rate from gun violence). SP can also be used to detect biases when assigning risk factors to people in the hiring process (risk factors include race and gender correlation to violence, laziness, incompetence), or explore other questionable attributes in datasets.
— Composed by: Austin Graham & Jasmine DeHart



Shine Xu presenting his work at the workshop and poster reception.
While attending this workshop, we noticed several relevant presentations coinciding with our lab projects and goals. In the upcoming paragraphs, we will discuss a few papers that stood out to us (with notable details and discussions from the talk).
Human-in-the-Loop Data Analysis: A Personal Perspective.
Anhai Doan (University of Wisconsin-Madison)
In the loop? Out of the loop? What’s the difference? Human-In-the-Loop-Data-Analysis studies the role of humans and develop human-centric techniques. When using machine learning and artificial intelligence, as developers, we want to prevent over fitting, machine bias, and poor implementation of algorithms. This paper studies the the benefits of having humans in the loop to help solve machine learning problems quickly, effectively, and with the consumers ideas in mind. As current HILDA works only address specific problems, the author suggests working on the big picture. In the author’s own words:
Going forward, I think we should devote more attention to examining “big picture” questions, such as “What is the scope of HILDA?”, “What are the important aspects that we should pay more attention to?”, “Where is the field going?”, and “What should we do to stay relevant and make major impacts?”. Exploring these questions help us understand the broader context of what we are doing, better evaluate our work, discover neglected topics, adjust our directions
if necessary, connect to other fields, and more. More importantly, it can help us understand if there is enough here to build a solid and coherent foundation for a new field, or if this is just a loose set of techniques.
From a personal perspective this is what Anhai Doan wants HILDA to accomplish:
- Solve Real Problems: Currently we solve abstract problems with opened goals and too many assumptions. In this section, he raised several questions about our measurements of success and hindrances with models. The end goals that real users care about are 90% precision and 80% recall. Will this raise problems of how to measure accuracy? What if our model can only reach 85%? How to debug our models?
- Build Real Systems: He refers to PyData, which is an existing system. He proposes that we build systems that real users can use. He believes that we should not build isolated monolithic systems. However, we should consider extending PyData, this creates an ecosystem for tools and weak research prototypes. The benefits of extending PyData include instantly leverage many capabilities, better convince many user to work with it, we will be able to teach PyData and its tools in classes, develop packing is much easier in academia and the whole community will focus on one system and we will see more progress.
- The last perspective of Anhai Doan was that we should codify a theory of Human Data Interaction.
Going forward data management will involve more humans in multiple ways. The HILDA community expects lots of engagement with HCI and AI communities. These other communities have also been working with ideas like HILDA, so what will make us stand out? Going back to our previous points, the community should seek to solve end to end problems for users and seek to build real systems.
Takeaways: The personal perspective by Anhai Doan on growing role of humans in data management and some important aspects of HILDA. This talk provides a food for thought to the researchers on a wide range of problems that will come under the HILDA’s scope. There are existing systems in python such as pandas, matplotlib, scikit-learn, pandas-profiling, and other packages to explore, profile, clean, transform, and perform analysis on the data and these systems are growing rapidly with introduction of new python packages. However, there is no single end-to-end system powerful enough to handle real-world applications. The single system that will work for whole community instead of isolated systems has significant benefits and will allow solving problems for real users.
— Composed by: Jasmine DeHart, Redae Beraki & Keerti Banweer
Optimally Leveraging Density and Locality for Exploratory Browsing and Sampling.
Albert Kim (Massachusetts Institute of Technology), Liqi Xu (University of Illinois Urbana-Champaign), Tarique Siddiqui (University of Illinois Urbana-Champaign), Silu Huang (University of Illinois Urbana-Champaign), Samuel Madden (Massachusetts Institute of Technology) and Aditya Parameswaran (University of Illinois Urbana-Champaign)
What is the best way to explore data? How can we find new trends and instances? This paper proposes a new and innovative fast query evaluation engine called NEEDLETAIL. This engine will let the analysts browse random samples and subsets of query results from large data sets. The focus of this paper was to address the any-k problem. This problem is finding a way to quickly return a small sample of records that satisfied the users specific needs, without requiring the returned items to be in the top bracket.
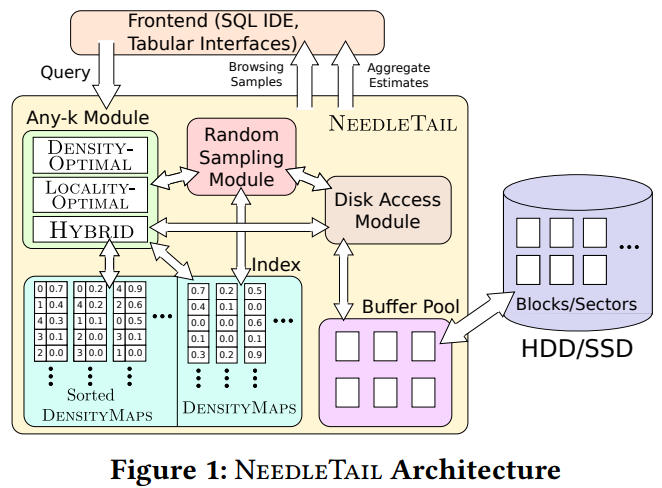
The paper addressed these main problems:
- Existing approaches include the bitmap index, but this is inefficient for the any-k problem. The authors found a need to develop a DENSITYMAPS and algorithms to address the any-k problem. DENSITYMAPS, unlike existing approaches, store an array of densities for each block of records. Each distinct value of the attribute has one entry in the array. DENSITYMAPS are much smaller than bitmaps. Even large datasets can easily fit in the memory. The information is indexed at the block level and the system can read/write in the sector. It stores the frequency of set bits per block. Overall, this method will consume less memory.
- Identifying which approach, density or locality, is the better approach. One comes at the cost of the other, so optimizing both at the same time is difficult. The authors implemented density optimal, locality optimal, and I/O optimal algorithms. The decision was to extend density and locality algorithms to create a hybrid. This hybrid leverages both density and locality optimal approaches. This method uses dynamic programming and reduces the cost of initial algorithms.
The paper also contributes to aggregate estimation, grouping and joining of queries. All in all, the NEEDLETAIL model is effective and efficient trade off between density and locality to help speed up the run times of queries.
— Composed by: Jasmine DeHart, Redae Beraki, & Keerti Banweer
Provenance for Interactive Visualizations.
Fotis Psallidas and Eugene Wu (Columbia University)
The core interaction logic with provenance is selections, logic over selections and multi-view linking. Interactive selection is to get subsets of inputs that correspond to selected visual outputs. For example, find the airports that operate in selected states. Alternately, logic over selections is to express application logic over the selected inputs. For example, find the number of airports that operate in selected states. Finally, multiple-view linking is to look at the relationships between different views. For example, show the distribution of number of flights per carrier only for selected states shown as below.
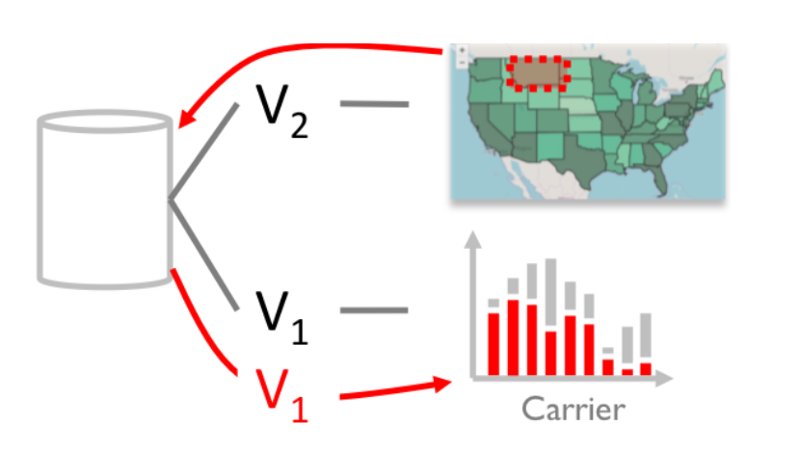
Interactive selections such as item selection, group selection, range selection and generalized selections can use a common provenance operation known as backward trace. Backward tracing refers to an operation where we wish to find the input data points that correspond to the visually selected ones; i.e. finding data for a state whose map was clicked on a map of the US.
Logic over selection such as tooltips, details-on-demand and semantic zooming can be expressed as queries that take the backward trace of the user’s selection as input. For example, if we have selected a number of states who have a population over a certain limit, and we want to know how many. Such a query would involve the backward tracing of the states, as well as applying the common COUNT SQL operation.
Multiple-view linking such as linked brushing and cross-filtering can be expressed by a backward trace followed by refreshing other views by executing the queries of the form selective_refresh(backward_trace()),where selective refresh is an update procedure that redraws selected views based on the query results.
Multi-application linking
Many applications are built over the same database or dataset. Extending multi-view linking to multi-application linking is possible; it can connect data across applications and reuse the application logic. The figure below shows linking between a running visualization with external applications.
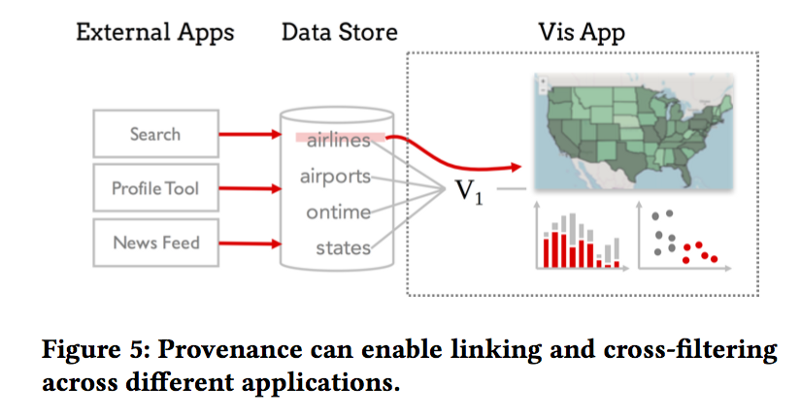
Takeaways: Data provenance ties heavily to the Human in-the-loop project hosted within our own lab. This application involves a visualization of a running learning algorithm a user may interact with to change certain metadata. To accomplish this, many of the operations described in this paper will need to be used to map user gestures on screen to metadata that will need changing.
— Composed by: Shine Xu & Austin Graham



From Left to Right: Doan, Xu, PsallidasWe started the SIGMOD conference with a bang!
The hardest part of our trip was done. Now, we could sit back and enjoy the remaining days and events to come. As a lab, we are extremely proud of Shine and his representation of himself, OU DALab, and the University of Oklahoma at the HILDA workshop. We found HILDA to be an eye opening experience to help unlock a realm of possibilities of how we can use human in the loop analytics for privacy, collaborative recommendation, machine learning, and of course, detecting Simpson’s Paradox.
This concludes our OU DALab @ HILDA 2018 (SIGMOD Series) blog! We hope you enjoyed our opinions and perspectives of the workshop as much as we enjoyed sharing them! If you have any questions, comments, or concerns about our blogs, feel free to contact us.
The upcoming blog will cover our experience at the DEEM workshop (co-located with SIGMOD 2018). Following the DEEM workshop, we will discuss what everyone is dying to hear about, SIGMOD 2018! Make sure to follow our blog to receive notifications about our new posts for SIGMOD 2018. As always, follow us on Twitter!