OU DALab @ DEEM Workshop (SIGMOD Series)
This post is the third in the SIGMOD 2018 series, click here for post 0, post 1.
On the final day of SIGMOD, we attended the DEEM workshop. DEEM is a workshop on Data Management for End-to-End Machine Learning. This workshop introduced many interesting ongoing research works which apply machine learning to address existing real world problems in data management and systems research.
“DEEM brings together researchers and practitioners at the intersection of applied machine learning, data management and systems research, with the goal to discuss the arising data management issues in ML application scenarios.” (DEEM Website)
The workshop chairs for DEEM were:
- Sebastian Schelter (Amazon Research)
- Stephan Seufert (Amazon Research)
- Arun Kumar (UC San Diego)

On the left, Data Science as intersection of Machine learning, Data Mining etc. On the right, Jens Dittrich giving academic keynote speech.The academic keynote was given by Jens Dittrich (Saarland University) on role of Data management in the new “AI-Tsunami”. He discussed the possible opportunities for research on the relationship between Machine Learning (ML) techniques and Data Management (DM).
One of the examples in the keynote was “The Case for Learned Index Structures” by Kraska et al. This research explores the use of deep learning models to replace the existing index structures. As per the preliminary results, use of neural networks gives performance 70% faster than cache-optimized B-Trees. This talk provided us with a fresh view on indexing, along with useful observations with some constructive criticism on adaptive indexing.

Matei Zaharia describing open research questions for applications supporting End-to-End ML.
The main idea of this workshop was discussing “arising data management issues in ML application scenarios”, theworkshop had another interesting talk on “MLflow: Supporting the End-to-End Machine Learning Lifecycle” by Matei Zaharia. This talk introduced an open source project to facilitate an open ML platform. This platform will addresses many problems faced by researchers in machine learning development such as challenges in tracking experiments, reproducing results etc. As stated by Zaharia, “MLflow introduces simple abstractions to package reproducible projects, track results, and encapsulate models that can be used with many existing tools”. For more details, you can visit this post “Introducing MLflow: an Open Source Machine Learning Platform” by Matei Zaharia.
The workshop presented different ongoing research projects and their preliminary results on applications that explore the role of Machine Learning in Data Management. In the following sections, we will discuss a few of the research projects presented in the DEEM workshop.
Learning State Representations for Query Optimization with Deep Reinforcement Learning
by Jennifer Ortiz, Magdalena Balanziska (University of Washington), Johannes Gehrke (Microsoft), Sathiya Keerthi (Criteo Research)
Query optimization in database systems is one of the most difficult tasks in database systems. The query optimizer is responsible for creating an execution plan the system will follow to return the correct results back to the end user. Most query optimizations done in existing database management systems (DBMSs) use statistical evaluations to estimate query cardinality, a component that tells the DBMS “you will have to do X amount of work to execute this plan”. This is the issue discussed in the present paper: the evaluations to estimate cardinality require a series of general assumptions about the underlying data (three mentioned are inclusion, uniformity, and independence) that lead to suboptimal query plans and thus slower executions.
The authors propose a method of reinforcement learning to replace the traditional statistical evaluation to create a more robust optimizer. The approach is centered on a neural network as follows:
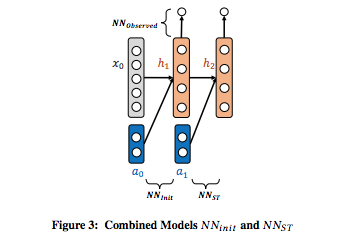
Proposed neural network architecture for cardinality estimation
The above figure shows two main functions: NN_init and NN_ST (underscore represents subscript). NN_init is a function mapping a vector x_0 which represents properties of a database and a_0 representing a relation operator into the input of NN_ST, a function that estimates the state transition function for reinforcement learning. The model is extended as shown in the figure below:
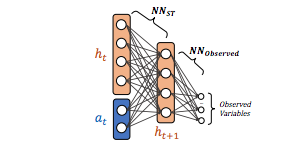
Extended architecture for cardinality estimation
The output of NN_ST is fed as input to function NN_Observered that generates the final cardinality estimations as observed variables. This model is recursive: these observed variables are used as inputs to the NN_ST layer.
Reinforcement learning is used to essential to define the state and reward encodings. The authors encode the current state using vector equi-join predicates and selection predicates found in the query; the vector contains a 0 if the predicate is not present, and a 1 otherwise. Elements in this vector are set to 0 during computation if the reinforcement agent selects the corresponding action. The reward function currently being experimented with is inversely proportional to the traditional optimizers cost estimation, however in the future the authors wish to experiment with the reward being inversely proportional to the query execution time in order to take into account physical plan properties.
The results of experiments are given here:
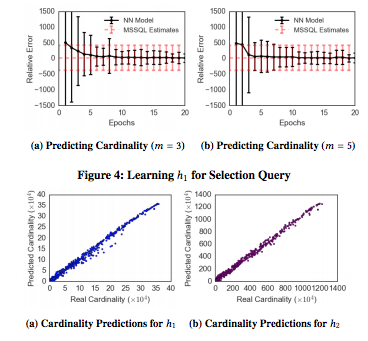
Cardinality estimation experiment results
In the top row, you can see at first the new approach is wildly variant. However, as time goes on the model begins to outperform SQL Server’s optimizer. The authors note that when more inputs are provided to NN_init, the time for convergence goes up. However, even with these extensions the current approach still eventually will outperform SQL Server.
Takeaways:
The new Software 2.0 methodology (replace common deterministic function with learned ones) is prevalent here. The authors state that as hardware performance goes up and costs go down that deep learning can be used for more and more performance-dependent tasks. This idea is demonstrated here, however the observation that as more inputs are added the time to train goes up is concerning. It would be interesting to see how the network performs with more inputs against known optimizers to find the point of diminishing returns. An open problem listed at the end of the paper is the choice of reward function and its effect on the resulting plan. An interesting extension of this work would be to define a list of reward functions that accomplish a task and how they effect the behavior of the optimizer. Doing this, you may allow certain optimization behaviors, or even construct another learner that learns best behaviors for a given situation.
— Composed by: Austin Graham
Exploring the Utility of Developer Exhaust
by Jian Zhang, Max Lam, Stephanie Wang, Paroma Varma, Luigi Nardi, Kunle Olukotun, Christopher Re (Stanford University).
In this paper, the authors use machine learning to explore developer exhaust: a byproduct of the data processing and analysis pipeline, such as logs, code and metadata. They mention that users rarely use developer exhaust systematically, instead only doing manual checks. They explore how to use exhaust to simplify complex downstream tasks, e.g., model search.
Log data generated when training deep learning models is the main focus in this paper to solve complex tasks such as model search: “by predicting the performance metrics for untrained models, log data is used to perform model search”. The preliminary experiments show promising results for use of developer exhaust to help learn models. Logs contain information about the performance of the models, e.g. training time, memory usage, etc. A lot of useful information exists in logs or metadata, which can be useful for solving complex tasks such as model search. Model search is the process of finding the best-performing model architecture for a specific task or method by training candidate architectures. The figure below shows the method where logs from pre-trained architecture are used in predicting the validation performance of untrained architectures.
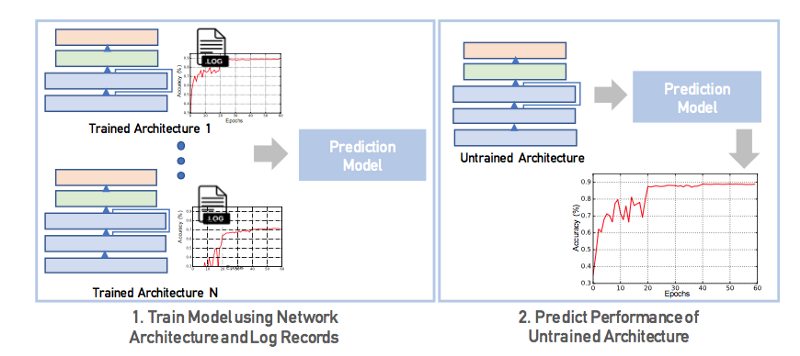
They define an edit distance between model architectures and predict model performances using nearest-neighbor approach. They design a LSTM-based regressor which serializes hyperparameters of a model as a sequence of tokens and trains an LSTM without any manual featurization to predict performance characteristics of an untrained model.
In the evaluation, predicted performance of untrained model based on training logs of other models close to true performance.
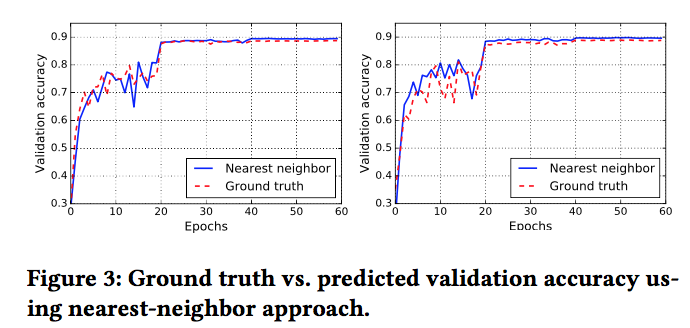
Their simple models can predict validation accuracy of a model within 2% of the true performance, and their method can predict performance given a constraint on training time.
Takeaways:
This research work has introduced an interesting approach to use the developer exhaust in ML applications to solve complex problems. This talk introduced opportunities for the use of logs or metadata, generated during the application of deep learning models that can assist in solving complex problems such as model search.
— Composed by: Shine Xu & Keerti Banweer
Accelerating Human-in-the-loop Machine Learning (HILML): Challenges and Opportunities
by Doris Xin, Litian Ma, Jialin Liu, Stephen Macke, Shuchen Song, Aditya Parameswaran (University of Illinois at Urbana-Champaign)
In machine learning workflow development, developers tediously process changes with iterative experimentation until desired results are obtained. Machine Learning (ML) models have numerous runs with trial and error before achieving the best accuracy. The development of machine learning models typically follow a similar workflow:
Developmental cycle of Machine Learning models
This is where Human-in-the-Loop (HIL) machine learning systems can come into play. This methodology can track changes and results in intervals. The prospect of this system will speed up iterations, give swift feed back, help make automation more accurate and so much more. The authors proposed HELIX, a system that speeds up iterative workflows. Adding an iterative human-in-the-loop aspect to machine learning models can reduce several deficiencies:
- Iterative reuse: Developer modifications can take minutes or hours to make even the smallest changes only to re-run the model from scratch.
- Introspection between iterations: Developers do not have an understanding the impact of modifications, debug performance and understanding performance.
- Leveraging think-time between iterations: ML systems do not use think time for background processes.
- Reducing iterative feedback latency: Current systems do not optimize for quick feedback.
- Automated cues for iterative changes: Developers need cues about subsequent changes form the ML model.
The goals of a HILML system are to shorten the time to obtain deploy-able models from scratch, eliminate the deficiencies in currently ML workflows, and support declarative specification of ML workflows. When developing a HILML system, there are prerequisites the system must obey.
- Usability: Declarativity and Generalization. The HILML system must be able to make generalizations for various use-cases, spanning workflow design decisions (supervised to unsupervised), and have expertise levels (novice to expert).
- Workflow DAG Model. The HILML system must be able to find and abstract different instances of the workflow as a DAG of intermediate data items. The DAG nodes relate to the output of certain operators and the edges show the input-output relationships in operators. Using the declarative specification, the HILML system ultimately gives the system a in-depth understanding of its workflow.
When building this type of ML workflow, developers can run into several challenges. The authors identify six main challenges that their model helps enable in the ML workflow.
- Intermediate Results Reuse
- Introspection: analyzing the impact of changes
- Automated background search during think time
- Quick feedback: end to end optimization
- Quick feedback: approximate workflow execution
- Automated cues for novice: change recommendations
The architecture for the HELIX system contains a programming interface, execution engine, and compiler for user application code.

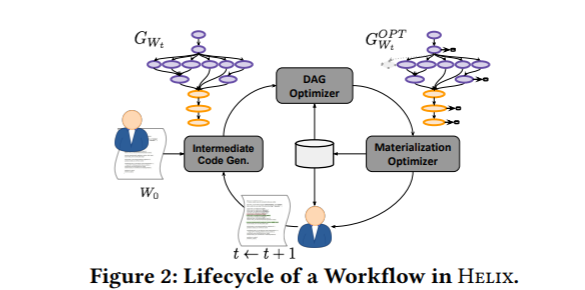
To evaluate the HELIX system, it was compared with two other similar systems, DeepDive and KeystoneML. One of the features of HELIX is that it only materializes intermediates to help reduce future run time. For classification, KeystoneML and DeepDive could not achieve HELIX’s order of magnitude reduction in run time.
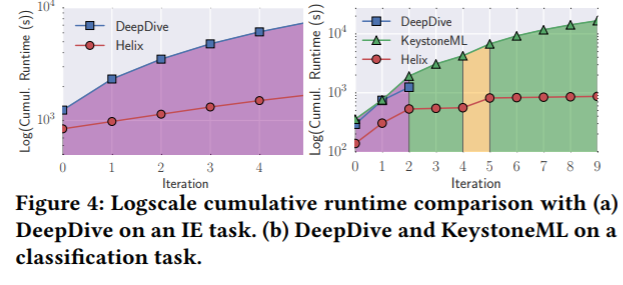
In conclusion, the authors created HELIX which is the first step to solving the various ML workflow problems. This system was built after finding a need for an efficient ML system for supporting HIL workflow development and iterative workflow. For more information on HELIX visit their project page.
— Composed by: Jasmine DeHart
Snorkel MeTaL: Weak Supervision for Multi-Task Learning
by Alex Ratner, Braden Hancock, Jared Dunnmon, Roger Goldman, Chris Ré
A major bottleneck for real-world machine learning problems is obtaining enough training data. I also have learned there exists another bottleneck by attending the presentation and by talking to Alex Ratner and Braden Hancock which is that most real-world machine learning systems involve multiple sub-tasks at different levels of granularity. They involve multiple related tasks and multiple types of labels. The paper proposes Snorkel MeTaL, an end-to-end system for multi-task learning. To achieve this, weak supervision techniques such as domain heuristics, distant supervision, crowdsourcing, and weak classifiers are used at multiple levels of granularity.
To handle this multi-task supervision challenge, we propose Snorkel MeTaL, a prototype system at the confluence of two recent technical trends: multi-task learning through shared structure in deep neural networks, and weak supervision denoised using statistical methods.

Alex Ratner presenting Snorkel MeTaL
In multi-task learning, separate tasks share similar parameters and with multiple tasks there is a better learned representation. But, hand-labeling is not an option when it comes to huge volumes of training data. They use data programming to create noisy but cheaper training data. In data programming, instead of hand-labeling training data, users write labeling functions (LFs). The responses of the LFs usually conflict and overlap. In Snorkel MeTaL, the collective outputs of these LFs are denoised with a hierarchical generative label model. The results from the generative model are the noise-aware probabilistic training labels and are used to train an auto compiled multi-task deep neural network. This end model will be able to generalize beyond it’s input sources.
To allow users to provide weak supervision at multiple levels of granularity, the hierarchically related tasks should be identified and then broken into a group of hierarchical decisions.
For example, suppose our goal is to train a machine learning model to perform fine-grained classification of financial news articles. By breaking this down into a hierarchy of tasks — e.g., company vs. money market articles, then sub-classes for each — we potentially make it easier to use available weak supervision at various different levels of granularity. We may, for instance, be able to use existing classifiers or other noisy labels for the ‘company vs. money market’ task, and then rely on pattern-matching heuristics to provide labels for the finer-grained sub-tasks.
The paper claims that Snorkel MeTaL achieved average gains of 9.5 and 11.2 points of accuracy over the weak supervision heuristics used and a baseline approach respectively.
The authors, as they promised at the presentation to release the source code of Snorkel MeTal, have now made it available on github.
— Composed by: Redae Beraki
With the common research interests of our OU DALab in applications of Machine learning in Data management and this workshop, it introduced to us the different challenges faced in applying machine learning to real-world scenarios. There are many research opportunities in end-to-end ML applications which need to be explored to address complex problems. The large-scale use of machine learning creates multiple challenges that need to be addressed by the data management research community, such as considering heterogenous target audience of ML application which includes analysts without programming skills on one hand and on the other hand, teams of data processing experts and statisticians. After attending the DEEM workshop, our team is motivated to explore different opportunities at the intersection of machine learning and data management.
This concludes our OU DALab @ DEEM 2018 (SIGMOD Series) blog! We hope you enjoyed our opinions and perspectives of the workshop as much as we enjoyed sharing them! If you have any questions, comments, or concerns about our blogs, feel free to contact us.
In the upcoming blogs we will cover our experience at SIGMOD Tutorials on Evaluating Interactive Data Systems, Modern Recommender Systems and Privacy at Scale. Make sure to follow our blog to receive notifications about our new posts for SIGMOD 2018. As always, follow us on Twitter!