The Recap: IEEE Symposium on Security and Privacy
Optimistic, proud, and eager are just a few words that encompass how I felt when I attended the 39th IEEE Symposium on Security and Privacy as a poster presenter. This was my first time attending a top tier conference as a PhD student. Looking back at my experience at the symposium, I gained valuable insight, immense inspiration, and everlasting connections. I would like to take you on this journey with me as I reflect on my experience at the 39th IEEE Symposium on Security and Privacy and my stay in San Francisco, California.


 Concluding my first year as a PhD Student, I had the pleasure of sharing my work at the IEEE Security and Privacy Poster Reception. IEEE Symposium on Security and Privacy is the leading conference for sharing advancements in computer security and electronic privacy. This conference brings researchers, practitioners, students, and general attendees from around the world in the fields of computer security and electronic privacy. The general chair for this symposium was Jason Li from Intelligent Automation, Inc. The program chairs for the symposium were Bryan Parno (Carnegie Mellon University) and Christopher Kruegel (University of California Santa Barbara). The symposium was held May 21 -23, 2018 at the Hyatt Regency in San Francisco, California.
Concluding my first year as a PhD Student, I had the pleasure of sharing my work at the IEEE Security and Privacy Poster Reception. IEEE Symposium on Security and Privacy is the leading conference for sharing advancements in computer security and electronic privacy. This conference brings researchers, practitioners, students, and general attendees from around the world in the fields of computer security and electronic privacy. The general chair for this symposium was Jason Li from Intelligent Automation, Inc. The program chairs for the symposium were Bryan Parno (Carnegie Mellon University) and Christopher Kruegel (University of California Santa Barbara). The symposium was held May 21 -23, 2018 at the Hyatt Regency in San Francisco, California.
During my stay in San Francisco, I stayed at an Airbnb hosted by Alice in the heart of Downtown San Francisco. It was minutes away from Union Square, China Town, and so much more. I had a great time wondering around and getting lost in the city. I ate at Sam Wo Restaurant, toured Chinatown’s Museum, strolled down Market Street, explored the Embarcadero Center, and wandered about Union Square.
San Francisco is full of modern day marvels and a plethora of opportunities to explore new things. Sticking to a tight schedule, the original business of attending the IEEE Symposium on Security and Privacy remained at the top of my priority list.
Day 1: Machine Learning & Privacy
The first day at the conference included several sessions like Machine Learning, Privacy, Side Channels, and Computing on Hidden Data. I began my day listening to several interesting talks and presentations. In those sessions, I found a few presentations that I believe are very relevant to my current project. The topics of the Day 1 are Machine Learning and Privacy; these sessions inspired me the most.
Session 1: Machine Learning
Session Chair: Tudor Dumitras
Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning. Presented by: Matthew Jagielski (Northeastern University)
This research started by using supervised learning techniques to manipulate machine learning. In supervised learning, there are two learning tasks to consider: classification and regression. Classification gives discrete outputs, such as classes. Regression gives continuous values, such as responses.
Poisoning is when an attacker adds a set of poisoning data points that will maximize the adversary objects where the corrupted model is learned by minimizing the loss function. Poisoning attacks have a few steps:
- Attacker adds points during training
- Model is influenced by attacker
- Predictions will be incorrect
The equation for a poisoning attack is shown below:
You start with a training set D and add poisoned data points, Dp, which will increase the objective of the adversary, Obj, where the corrupted model (Op) is learned from the loss function.
To fully understand their threat, they look into two adversaries using white and black boxes. In white box attacks, the attacker knows everything. In black box attacks, the attacker can only query access to models. When assessing both of these threat models, the goal of the model is to maximize the models corruption.
To do this, the authors used optimization-based poisoning attacks. This attack uses gradient ascent (greedy approach) and iteratively updates at each point. This attack stops at the convergence and outputs poisoning points. In the image below, the author displays previous work that is similar to the suggested approach.

Matthew Jagielski presenting their work at the conference
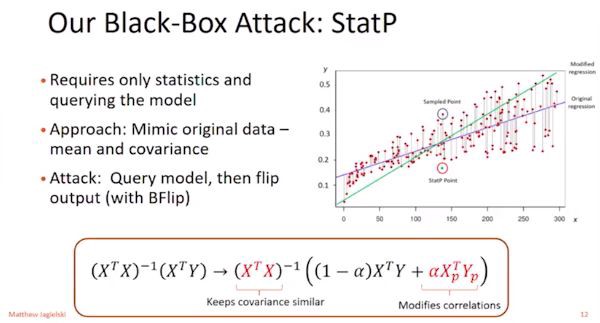
The author suggest the use of their white box attack, OptP. OptP derives optimization for both x and y values, uses BFlip (push furtherest possible), and combines regularized training loss and validation set loss.

Along with their white box attack, they also create a black box attack called StatP. This model only uses statistics and queries. To complete this attack, the adversary must mimic original data (i.e. mean, covariance). When attacking, you must query the model and then flip the output via BFlip.
For defending against these attacks, the authors created a defense called TRIM. TRIM estimates the models parameters and finds the lowest residual points.

This work showed poisoning attacks on regression models while creating a white box attack (OptP), a black box attack (StatP), and a defense (TRIM). Through evaluations it is found that OptP is slower in comparison to StatP which takes seconds.
Session 2: Privacy
Session Chair: Carmela Troncoso
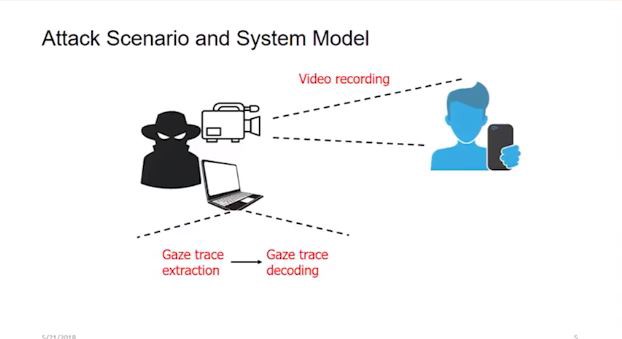
EyeTell: Video-Assisted Touchscreen Keystroke Inference from Eye Movements. Presented by: Yimin Chen (Arizona State University)
In comparison to previous works (Video-based, Sensor-based, WiFi-based), these author’s propose a system that does not require capturing finger movements or sensor data. This model assumes that an attacker can capture eye movements from the victim. From the video, the attacker an infer the victims keystrokes from their eye movements.
One technique to use is Gaze Trace Extraction. This technique adopts and adapts to each user’s unique eye movements. Gaze Trace Extraction is done in three simple steps: eye detection, limbus detection, and gaze extraction. The author focuses on pattern locks, pin keyboards, and alphabetic keyboards in their examples.
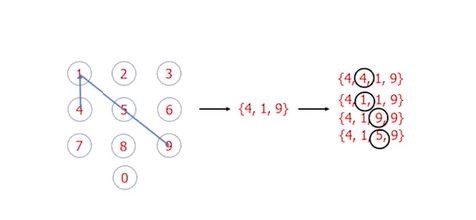
Pattern lock: typically a sliding pattern on screen. Attackers can execute Gaze Trace Decoding. For this model the first step is trace segmentation which is looking for a turning point between two segments. The next step is Segment Decoding. When given an arbitrary number of segments, we must normalize the segments and find the legitimate candidates. Finally, an attacker would use Candidate Pattern Generation (as seen below).

Yimin Chen presenting their work at the conference
After the candidates are generated, there are some heuristic rules that will be used for candidate ranking. Candidate Ranking follows three rules:
- Follow the order of pattern generation.
- Result with longer total length has higher ranking.
- Staring point decides the order.
PIN keyboard: typically a tapping pattern on screen.
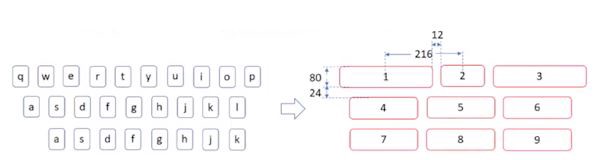
Alphabetic keyboard: the number of segments are unknown and has more keys.
To extract this information, the alphabetical keyboard is transformed into a quasi-PIN keyboard so the attacker can use the previous technique.
For their experiments, the authors used a camcorder, iPhone 6s (PIN and Alphabetical), and Google Nexus 6 (Pattern). For this study, they also recruited 22 participants (5 females, 17 males). When evaluating results, they used the top k metric for each scenario. The authors found that the limitations of the study includes inference accuracy due to noise and limitations in eye tracking technique used by the attackers.
Poster Reception
Concluding Day One, the poster reception followed shortly behind the last session. The research project I presented at the 39th IEEE Symposium on Security and Privacy is the work I am conducting with the University of Oklahoma Data Analytics Lab under the direction of Christan Grant, PhD. Visual Content Privacy Leaks on Social Media Networks is an ongoing effort to reduce visual content (images and video) leaks posted on social media networks from typical users with the use of various mitigation techniques. This project will be used as a mechanism to bring awareness to users about the potential privacy leaks and their immediate dangers.
I had a blast explaining my work, project goals, and the need for this research. There were any people at the reception that gave me great insight for expansion of my work and there were others that found inspiration from my work. My project is developing swiftly, you can follow me or OU DALab on twitter for timely updates.

Jasmine DeHart presenting her poster at IEEE Security and Privacy Poster Reception
Day 2: Understanding Users
Understanding Users, Programming Languages, Networked Systems, and Program Analysis were the main sessions for the second day. From these sessions, I found ‘Understanding Users’ to be very important in understanding user perspectives and motives for my work.
Session 5: Understanding Users
Session Chair: Sascha Fahl
The Spyware Used in Intimate Partner Violence. Presented by:Rahul Chatterjee (Cornell Tech)
Is your phone’s battery always dying fast? Is your phone running hot majority of the time? Do you feel like your being watched? Well, maybe you are. Dealing with a control and insecure partner, can lead to Intimate Partner Violence (IPV). IPV is any sexual violence, physical violence or stalking by a significant other. The rates of IPV are higher with women (25% of the female population) than men (10% of the male population). Technology today is abused for IPV. With this technology abusers can:
- Send harassing messages
- Stalk partner online
- Distribute non-consensual pornography
- Spy on victims using spyware
Intimate Partner Surveillance (IPS) the abuser is using the abused cellular device to install spyware. Usually the abuser has physical access to the device, knows the password, and the abuser might have purchased the device for the abused. In these cases, the abuser can easily install spyware.
The authors ask four main questions before conducting this study.
- What spyware tools are available to abusers?
- How easy is it to find and (ab)use them?
- Are developers of their tools complicit in IPS?
- Can anti-spyware apps come to the rescue?
The authors did an in-depth study of the spyware ecosystem. Astonishingly, they found 4000 IPS relevant apps and several with dual use. Online there are abundant resources for abusers to learn about how to use spyware (blogs, videos, forums). Currently, anti-spyware does not flag IPS apps as threats. It is noted that spyware ecosystems are empowering abusers.

RChatterjee presenting their work at conference
To counteract these types of attacks, the authors built a snow ball searching technique. This technique uses regex to filter and remove unrelated terms. To test this methodology, the authors crawled on Google, Google play, and iTunes finding 3,500+ IPS relevant apps in app stores. The types of applications that are relevant to IPS contain:
- overt spyware app used for IPS
- dual spyware app functionality can be re-purposed for IPS
Some developers promote spyware via IPS with posts containing words like “How to spy..” and “…mobile spy application”. Others seem to condone IPS features. It was found that many applications used for parental controls can also be used for IPS. These findings have be disclosed to Google and Google has tightened enforcement on playstore applications.
While conducting this study, they found 40 applications that have anti-spyware features, however the application does not detect dual use apps. In the future, it is imperative to set guidelines for honest developers to prevent IPS. They would also like to see collaboration with Google and Symantec.
Day 3: Authentication
The final day wrapped up the conference covering topics like Web, Authentication, Cryptography, and Devices. From these talks, I found Authentication to be topic.
Session 10: Authentication
Session Chair: Gang Tan
When Your Fitness Tracker Betrays You: Quantifying the Predictability of Biometric Features Across Contexts. Presented by: Simon Eberz (University of Oxford)
What are biometrics? What machines use biometrics? Biometrics are the body measurements and calculations from human characteristics. These human characteristics can include fingerprints, facial structure, eyes, and even walking. A typical smart phone has fingerprint recognition, facial recognition, eye scans, and a basic health app which tracks steps (walking, running, climbing). Beyond a cellular phone, there are other technologies that track biometric features (e.g. watch, pedometer, security systems).
Behavioral biometrics have become a sweet spot for attackers. After collecting the victim’s information, the attacker works to train themselves to imitate the victim’s biometrics. Attackers use touch dynamics, gait (walking), keystroke dynamics, and ECG (i.e. heart beat patterns) to make attacks. During these attacks there are two phases, (1) collection of victim’s biometric data and (2) carrying out presentation or mimicry of victim. This paper works to solve phase 1, the collection of the victim’s biometric data. This can be done by analyzing where an attacker get information from and how useful this information will be to an attacker.
For example, imagine someone doing a cardio workout. The person can use a watch, phone, or even a chest tracker to record fitness activities and other biometrics. With each device, all results will be different.
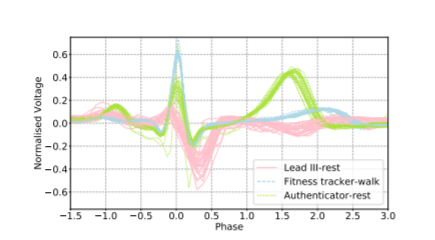
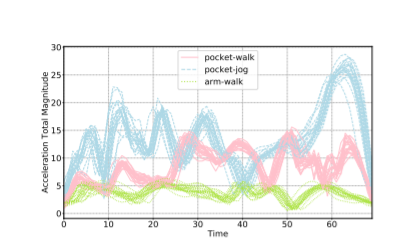
Creating specific feature distributions becomes a huge challenge because of this inconsistency among various biometric tracking technologies. The question then becomes “Are these changes systematic across users?”. This research has two goals (1) calculate the predictability of features across contexts and (2) minimize the distance between the source and target features. These goals can be achieved by learning cross context changes from population statistics. This work used five biometrics eye movements, mouse movements, touch screen inputs, gait, and ECG.

Simon Eberz presenting their work
The authors present a method for calculating an unpredictability score. You can think of the unpredictability score as the security score for the biometrics. A lower score would mean there are more predictive features, hence the security of those features is lower.
They found that eye recognition and touch dynamics are easier for users to predict. They also found that gait is a harder feature to predict because of the changes in patterns (walking vs running). Older data collected from biometric technology is no longer relevant after a certain time span. With that data, it will be harder to predict current patterns (gait, touch dynamics).
This work proposed a framework to measure cross context feature predictability and identified and selected resilient features from biometrics. This work can be used to compare biometric systems, identify vulnerable target contexts and problematic sources. Future work includes finding a method to engineer stronger features to make the data more unpredictable.
The Windup: Closing Remarks
I enjoyed these presentations and reading more about their works. Privacy and security encompasses a multitude of topics across the spectrum of life. I find that there can be an intersection between my work and many others. Let’s say that a typical user posts an image or video on a social media network. Beyond looking for privacy leaks (such as keys, cards, and baby faces), we can look further into that visual content for biometric data like eyes movements, facial structure, and even fingerprints which can also be connected to valuable pieces of personal identifiable information. Even looking into an IPV scenario, the potential danger of IPV/IPS can lead to increased visual content privacy leaks on social media networks. These consequences could omit the attacker and bring damage exclusively to the victim.
I found S&P to be an eye opening experience to help unlock a realm of possibilities for expanding my project objectives and opportunities for collaboration. I hope you enjoyed my opinion and perspective of the symposium as much as I enjoyed sharing them! If you have any questions, comments, or concerns about my blogs, feel free to contact me.
Make sure to follow our blog to receive notifications about our new posts for the upcoming 40th IEEE Symposium on Security and Privacy. As always, follow us on Twitter!