DALab meeting for discussing the paper “A Framework for Understanding Unintended Consequences of…
As usual, we have our DALab meeting today. I presented Suresh’s paper 1 related to bias in the ML process. Firstly, we talked about the bias occurring in the ML, and how to define the bias. Bias can be from the data and the algorithm. In different phase of the ML process, data can be biased since data is the product of a process.
I used the illustrative scenario from the paper to show the different biased causing by different factors. Introducing more data solved the lack of data on women issue for detecting women smiling is pretty straightforward. Collecting more women samples for predicting the proper job candidate doesn’t help to improve the model’s behavior. The bias talked in this example is not clearly until the proxy label indicating representation bias came out. Since the proxy process is biased, even more data can not solve the representation bias. But if we can fix the proxy process, the bias may be mitigated.
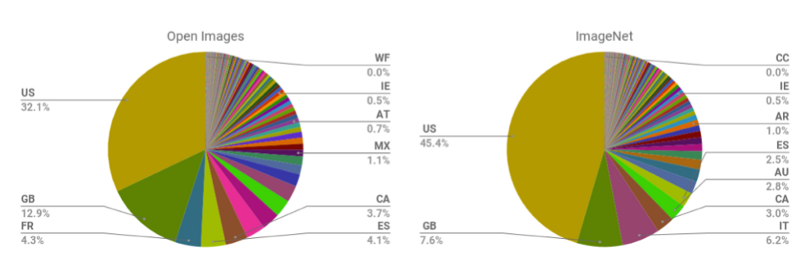
We starts from historical bias. I showed a result from searching CEO in google to bring the discussion. Should the result reflect the actual women CEO proportion? Different opinions from different people. Before we go through representation bias, the disproportion of the data was aware in this moment. I used two figures showing the distribution of the image data kept in different countries 2. People are surprised about those disproportion situation.
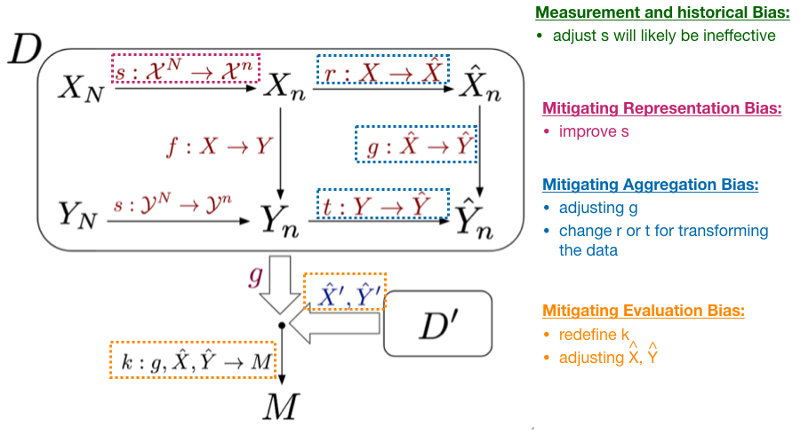
Measurement bias are choosing and measuring the data feature of interest, and aggregation bias arises when we can not find a one-size-fit-all model. We also discuss about the benchmark data set for the evaluation bias and realized that the benchmark dataset may not split equally for different subgroups.
I also show our group the mapping figure in ML pipeline. Now we can have a common language to discuss about bias in the ML process.
You can find our slides in the following link: https://www.slideshare.net/chguxu/lab-presentation-a-framework-for-understanding-unintended-consequences-of-machine-learning-139763234
The original paper: https://arxiv.org/pdf/1901.10002.pdf
-
Suresh, Harini, and John V. Guttag. “A Framework for Understanding Unintended Consequences of Machine Learning.” arXiv preprint arXiv:1901.10002 (2019).](https://arxiv.org/pdf/1901.10002.pdf) ↩
-
Shankar, Shreya, et al. “No classification without representation: Assessing geodiversity issues in open data sets for the developing world.” arXiv preprint arXiv:1711.08536 (2017). ↩